Entity Framework Core: Tracking vs. No Tracking Queries – What are the differences and how does it work?
Currently Entity Framework Core has 3 different behaviors to handle query tracking, Tracking, No Tracking and No Tracking With Identity Resolution.
In this article I will go over each one of them and compare the main differences in practice. For that I will be sharing code samples that can be found in this GitHub repository: TrackingVsNoTracking.
For this project, only two entities were created, Team and Player. A team has many players, but each player has only one team, so we have a one-to-many relationship.
The entities were mapped using the concept of Fluent API and AutoInclude was defined by default, then when querying players in the database the teams will automatically be included.
The database is initialized with 2 teams and 100 players, 50 players per team.
Now that we have a briefing of the solution, let's better understand the behavior of tracked and untracked queries and see some practical examples.
Tracking
Every query that returns entity types by default is Tracked, it means that internally a dictionary of tracked instances is maintained by EF Core, for that reason when new data is loaded the dictionary will be checked to see if the key of a given instance is already tracked. Any modification in those instances will be detected and when the SaveChanges method is called the changes will be persisted in the database.
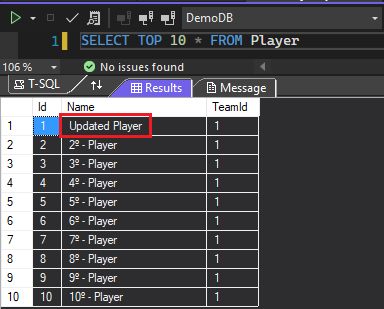
See the code snippet below. All 100 players registered in the database are being queried and the first one is being updated.
At line 5 the name of the first player is being updated, therefore EF Core will identify this change and modify the instance status to this record in memory. At line 6 SaveChanges method is called, as a consequence after that the changes will be persisted in the database, as we can see in the image below:
When the data is returned by a tracked query, EF Core will check if the entity is already in the context, if so it will be possible to reuse existing instances rather than creating a new one, this is called identity resolution.
Using Microsoft Visual Studio Community 2022 diagnostic tool, after fetching players from the database, we can see that we have 2 different instances of teams and 100 instances of players in memory (a breakpoint was added in the fifth line of the previous code snippet, in order to generate the snapshot below). EF Core is smart enough to identify that even though we have 100 players there are only 2 different teams and instead of creating a new team instance for each players, one single reference of the respective team instance is kept for players, furthermore we can see that in addition to the main entity (players), related objects are also tracked.
No Tracking
Entities returned from the database will not be tracked, thus queries will be executed faster, since there is no need to maintain an internal control to detect changes. When untracked entities are modified and the SaveChanges method is called the changes will not be persisted in the database, as we can see in the example below:
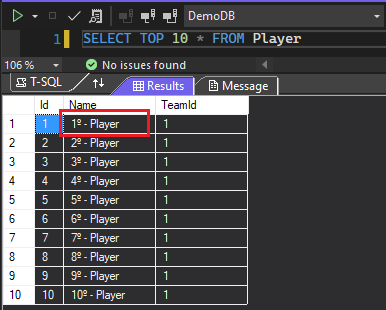
It is useful for read-only queries, however, be aware that since untracked queries do not perform identity resolution, multiple instances of the same record can be created in memory, as we can see in the example below, where 100 different instances of teams were found in memory, instead of one single instance for each team, as was the case in the previous example for tracked queries.
No Tracking With Identity Resolution
This behavior was implemented in EF Core 5.0 and basically it is a combination of the previous behaviors. As with No Tracking, changes to entities returned from the database will not be detected, however identity resolution will be performed to ensure that all equal occurrences of the same entity will be represented by a single instance, then there will be no duplicate objects in memory.
Untracked queries with identity resolution are slightly slower than untracked queries, but still faster than regular queries that use full change tracking.
Configuring Query Tracking Behavior
By default all EF Core queries are tracked and can change this behavior using extension methods for specific queries, as exemplified in the previous examples, however there are two more ways to configure.
The first is globally, applying the desired pattern directly by overriding the OnConfiguring method in the database context, as shown below:
The second one is defining this configuration by instance of the context, so while the instance is being used the defined behavior will be executed. Below is an example of this type of configuration:
Conclusion
We already know that EF Core tracks entities by default, and this makes it easy to apply changes to entities, which can be persisted in the database later. This is a very powerful feature of the framework, but this behavior is preferable when we intend to make changes.
Untracked queries are ideal in scenarios where we just want to retrieve data that will not be updated (a single record, data for a report or a collection for a combobox, for example), in which case we will have a slight performance boost, but remember that using untracked queries in scenarios where many identical related records are found, EF Core will not be reusing same instances, in consequence many unnecessary instances will remain in memory and it may cause huge application performance degradation, especially when the data returned from the database is heavy (when there are images stored, for example), however, currently there is already a solution to handle scenario like that, we can use No Tracking With Identity Resolution and combine read-only queries with identity resolution and thus we will have better performance while avoiding duplicate data in memory.
brilliant explanation, i really liked the way you demonstrated how the objects instances work in memory
thanks!
Excellent article, thank you.